《TCP/IP 详解:卷 1》¶
阅读信息
- 评分:⭐️⭐️⭐️⭐️⭐️
- 时间:07/17/2023 → 05/20/2024
- 读后感:本书作为网络协议方面最权威和最重要的书籍,非常全面和详细讲解了方方面面的知识点,但其中一些相关性不是很强的内容可以快速略过,把注意力集中于 TCP 部分。另外,书中使用了大量的 Wireshark 抓包示意,可根据 Wireshark 官方文档来学习下抓包分析,加强记忆并具有排查网络故障和性能分析的能力。
协议层级¶
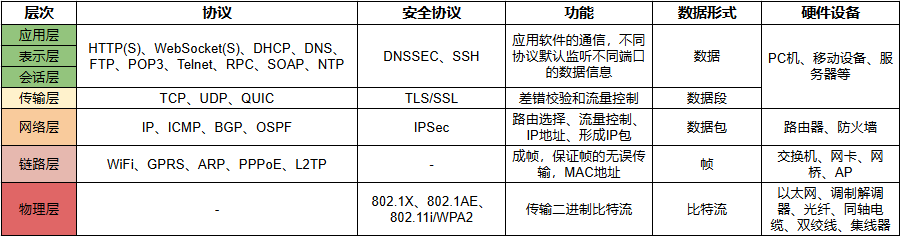
协议层级对比 
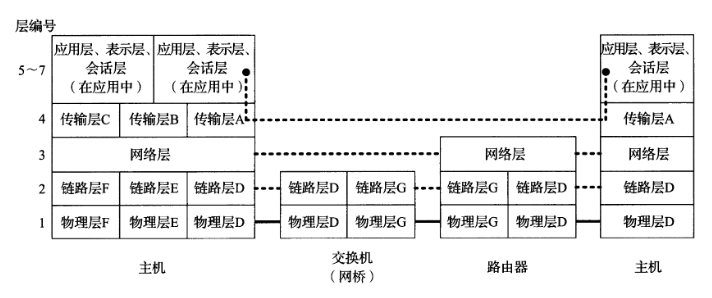
协议封装与分用
标准的端口号由 Internet 号码分配机构(IANA)分配。这组数字被划分为特定范围,包括熟知端口号(0-1023)、注册端口号(1024-49151)和动态/私有端口号(49152-65535)。
IPv6 地址中的冒号分隔符可能与其他分隔符混淆,如 IP 地址和端口号间的冒号,此时需要使用[]来包裹 IPv6 地址,如 http://[2001:0db8:85a3:08d3:1319:8a2e:0370:7344]:443/
广播指一人对所有人通信,组播指一人对多人通信。
数据链路层¶
ARP¶
ARP 是 IPv4 的专有协议,IPv6 引入了 NDP(Neighbor Discovery Protocol,邻居发现协议)。NDP 提供了与 ARP 类似的功能,用于将 IPv6 地址解析为链路层地址(如 MAC 地址),以便在网络中正确地发送数据包。NDP 协议被合并到 ICMPv6 中。
ARP 协议工作于局域网。当访问局域网内服务时,需要在以太网帧中含源主机和目标主机的 MAC 地址。而通过互联网访问远程服务时,只需要在以太网帧中包含源主机的 MAC 地址。一旦数据包离开局域网,并进入到广域网中,它会经过多个网络设备和路由器,最终到达目标主机。在这个过程中,以太网帧中的目标主机 MAC 地址会被替换为下一跳路由器接口的 MAC 地址(这也是数据链路层负载均衡的实现方式),以便正确地将数据包传递给目标主机。
ARP 协议的攻击有欺骗应答和修改静态条目。
网络层¶
IP¶
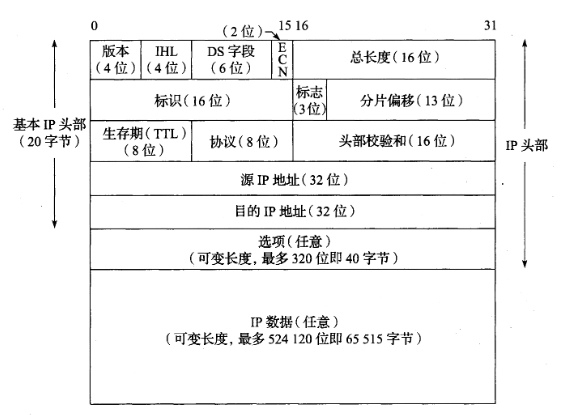
IPv4 头部字段(头部大小可变) 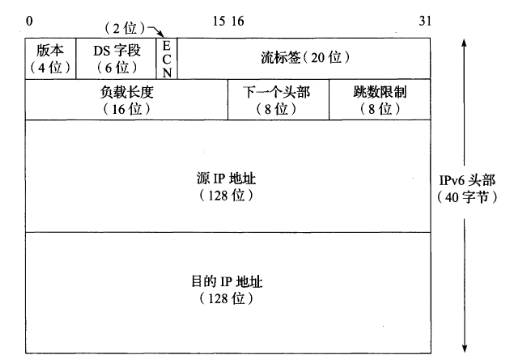
IPv6 头部字段(头部大小固定 40 字节)
IPv4 头部与 IPv6 头部除了版本外,再无其它相同字段。
| 前缀 | 特殊用途 | 参考文献 |
|---|---|---|
| 0.0.0.0/8 | 本地网络中的主机。仅作为源 IP 地址使用 | RFC1112 |
| 10.0.0.0/8 | A 类专用网络(内联网)的地址。这种地址不会出现在公共 Internet 中 | RFC1918 |
| 127.0.0.0/8 | Internet 主机回送地址(同一计算机)。通常只用 127.0.0.1(可简写为 127.1) | RFC1112 |
| 169.254.0.0/16 | "链路本地"地址,只用于一条链路,通常自动分配(Windows 无法连接网络时常有此 IP) | RFC3927 |
| 172.16.0.0/12 | B 类专用网络(内联网)的地址。这种地址不会出现在公共 Internet 中 | RFC1918 |
| 192.0.0.0/24 | IETF 协议分配(IANA 保留) | RFC5736 |
| 192.0.2.0/24 | 批准用于文档中的 TEST-NET-1 地址。这种地址不会出现在公共 Internet 中 | RFC5737 |
| 192.88.99.0/24 | 用于 6to4 中继(任播地址) | RFC3068 |
| 192.168.0.0/16 | C 类专用网络(内联网)的地址。这种地址不会出现在公共 Internet 中 | RFC1918 |
| 198.18.0.0/15 | 用于基准测试和性能测试 | RFC2544 |
| 198.51.100.0/24 | TEST-NET-2 地址。被批准用于文档中 | RFC5737 |
| 203.0.113.0/24 | TEST-NET-3 地址。被批准用于文档中 | RFC5771 |
| 224.0.0.0/4 | IPv4 组播地址(以前的 D 类),仅作为目的 IP 地址使用 | RFC1112 |
| 240.0.0.0/4 | 保留空间(以前的 E 类),除了 255.255.255.255 | RFC0919 |
| 255.255.255.255/32 | 本地网络(受限的)广播地址 | RFC0922 |
| 前缀 | 特殊用途 | 参考文献 |
|---|---|---|
| ::/0 | 默认路由条目。不用于寻址 | RFC5156 |
| ::/128 | 未指定地址,可作为源 IP 地址使用 | RFC4291 |
| ::1/128 | IPv6 主机回送地址,不用于发送出本地主机的数据报中 | RFC4291 |
| ::ffff:0:0/96 | IPv4 映射地址。这种地址不会出现在分组头部,只用于内部主机 | RFC4291 |
| ::{ipv4-address}/96 | IPv4 兼容地址。已过时,未使用 | RFC4291 |
| 2001::/32 | Teredo 地址 | RFC4380 |
| 2001:10::/28 | ORCHID(覆盖可路由加密散列标识符)。这种地址不会出现在公共 Internet 中 | RFC4843 |
| 2001:db8::/32 | 用于文档和实例的地址范围。这种地址不会出现在公共 Internet 中 | RFC3849 |
| 2002::/16 | 6to4 隧道中继的 6to4 地址 | RFC3056 |
| 3ffe::/16 | 用于 6bone 实验。已过时,未使用 | RFC3701 |
| 5f00::/16 | 用于 6bone 实验。已过时,未使用 | RFC3701 |
| fc00::/7 | 唯一的本地单播地址,不用于全球性的 Internet | RFC4193 |
| fe80::/10 | 链路本地单播地址 | RFC4291 |
| ff00::/8 | IPv6 组播地址,仅作为目的 IP 地址使用 | RFC4291 |
大端序与小端序¶
- 大端序(Big Endian,也称为高位优先):在大端序中,高位字节(Most Significant Byte, MSB)放在低地址,低位字节(Least Significant Byte, LSB)放在高地址。
- 小端序(Little Endian,也称为低位优先):在小端序中,低位字节(LSB)放在低地址,高位字节(MSB)放在高地址。
大端序更符合人类从左向右的阅读习惯,而小端序则更适合低位优先的运算(如位移、比较、加法等)。
由于 x86 之前的 IBM、Sun Microsystems 等系统都采用大端序,且网络协议中的字段采用大端序更有利于人类阅读和理解,因此许多网络传输协议采用了大端序。
虽然采用小端序的 x86 在接收到采用大端序的网络数据包后需要转换,但这个转换并不会带来明显的性能损失,这是因为现代操作系统和网络堆栈已经优化了这个过程,并且硬件也提供了加速功能,使得字节序的转换变得更加高效。
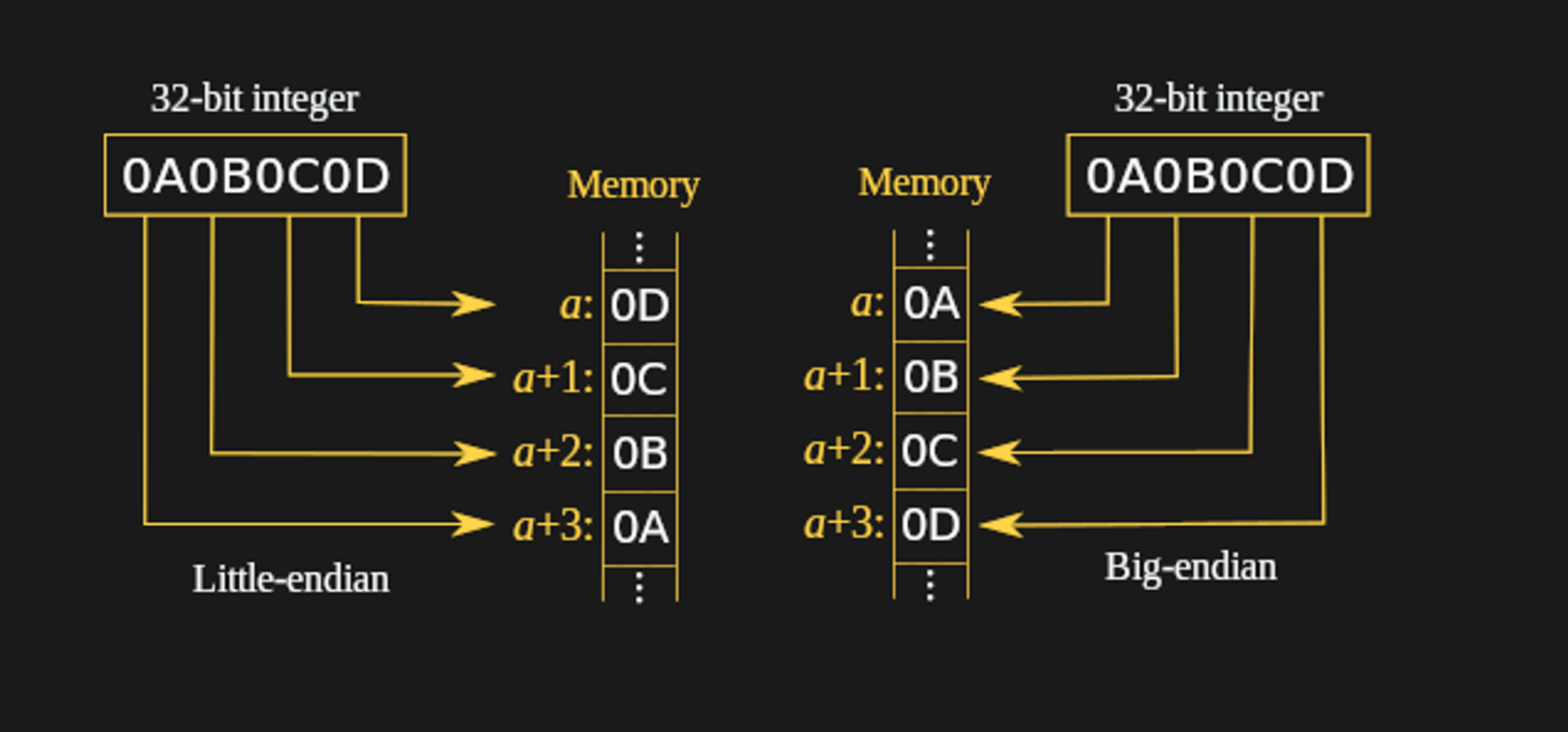
大端序应用于:
- 网络传输:大部分网络协议采用大端序进行数据传输,例如 TCP/IP 协议栈中的 IP、UDP 和 ICMP 等协议。
- 大整数运算:在一些大整数运算算法中,如 RSA 加密算法
小端序应用于:
- x86 架构:大部分 x86 架构的处理器都采用小端序,包括 Intel 和 AMD 的处理器
- 内存操作:在内存中,小端序的排列方式可以提供更高效的访问。因为低位字节在低地址,与 CPU 的读写操作一致,可以直接按照地址顺序连续读取
- 存储设备:一些存储设备使用小端序来存储数据,如 Intel 架构的硬盘。在这种情况下,使用小端序可以直接将数据从存储设备读入内存
NAT¶
NAT 被用于缓解 IPv4 枯竭的问题,但 NAT 的流行严重阻碍了 IPv6 的推进进程。
NAT 需要重写数据包的寻址信息,以便私有地址空间的系统和 Internet 主机之间能够正常通信。
NAT 包括基本 NAT 和 NAPT(Network Address Port Translation,网络地址端口转换)。基本 NAT 只会重写 IP 地址,而 NAPT 则会重写 IP 和端口。

NAT 中的映射关系将在交换 FIN 数据包后被删除。
防火墙¶
该部分内容推荐查看 Linux 防火墙 - 鸟哥
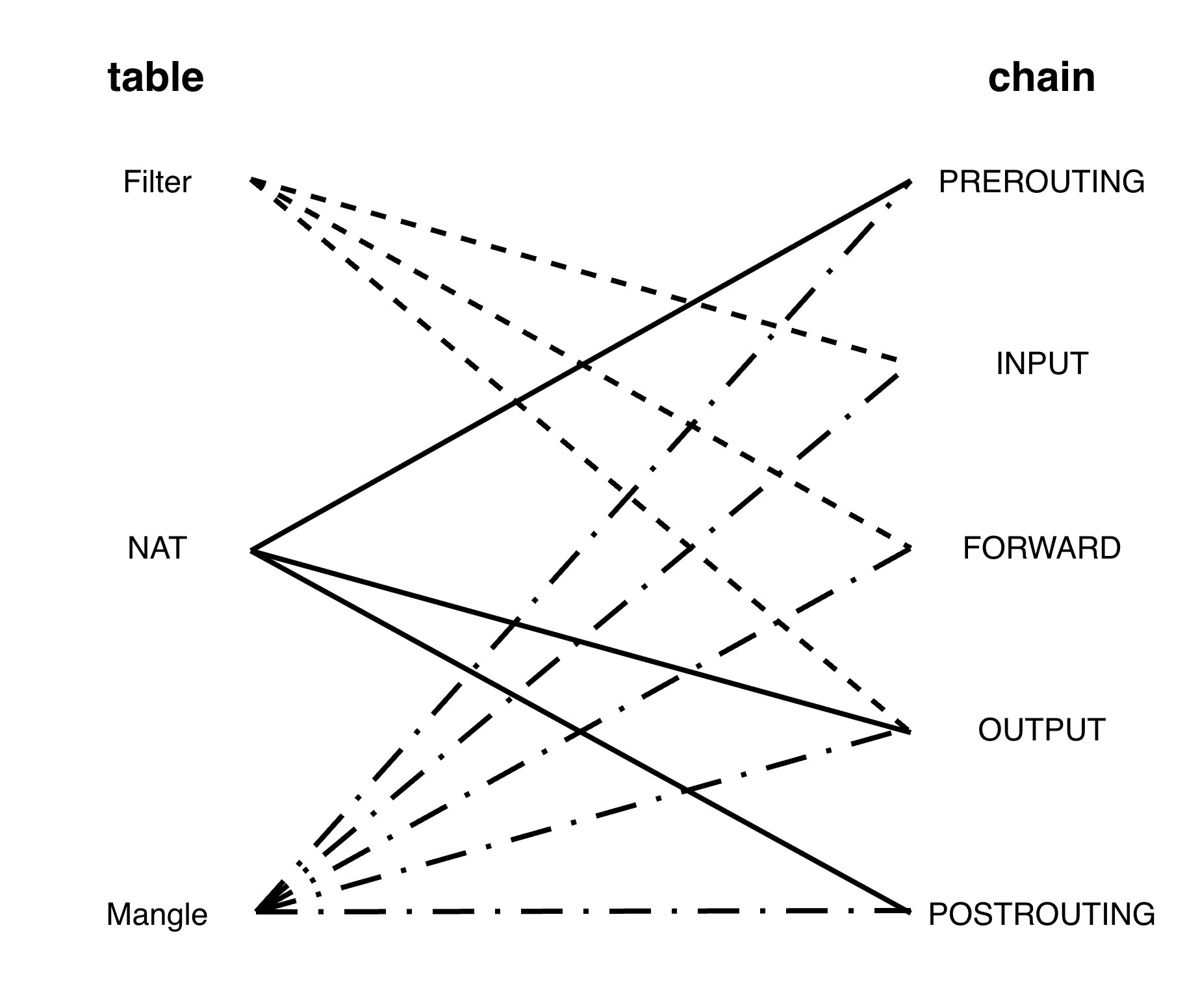
iptables 是用 NetFilter 的网络过滤功能构建的。iptables 由 table(过滤表)和 chain(过滤链)组成:
- table
- Filter:主要用于实现防火墙规则,允许或拒绝特定的数据包通过系统中的每个网络接口
- NAT:主要用于修改数据包的源 IP 地址和目标 IP 地址,以便实现端口转发、负载均衡等功能
- Mangle:用于修改数据包的头部信息。它可以改变数据包的 TTL(Time to Live)、Type of Service(ToS)等字段,还可以标记数据包以供后续处理
- chain(依据流量处理顺序排序)
- PREROUTING:链在数据包进入路由决策之前进行处理
- INPUT:链用于处理目标地址是本机的数据包
- FORWARD:链用于处理转发到其他主机的数据包
- OUTPUT:链用于处理源地址是本机的数据包
- POSTROUTING:链在数据包离开系统之前进行处理
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.1.0/24 -j SNAT --to-source <eth0 IP>
通过这个规则,内部网络上的流量将被转发到外部网络,并且其源 IP 地址将被更改为 eth0 接口的 IP 地址。这样,从外部网络看,所有来自内部网络的流量都似乎来自于 eth0 的 IP 地址。
nftables(Netfilter Tables)作为 iptables 的工具,具有以下优势:
- 性能更高:与 iptables 相比,nftables 在处理大量规则时性能更好
- 更简洁的语法:nftables 引入了一种新的配置语言,使配置规则更加直观和易读
- 更强大的匹配和过滤:nftables 提供了更多的匹配选项和过滤功能,以便更精确地控制网络流量
- 支持动态更新:nftables 可以动态地添加、修改和删除规则,而无需重新加载整个防火墙配置
ICMP¶
ICMP 使用 IP 协议进行传输,严格来说,它是位于网络层与传输层之间的协议。
由于黑客在大量攻击中使用 ICMP 报文,因此网络管理员经常会用防火墙封锁 ICMP 报文,从而导致 ping、traceroute 等无法正常工作。
传输层¶
TCP¶
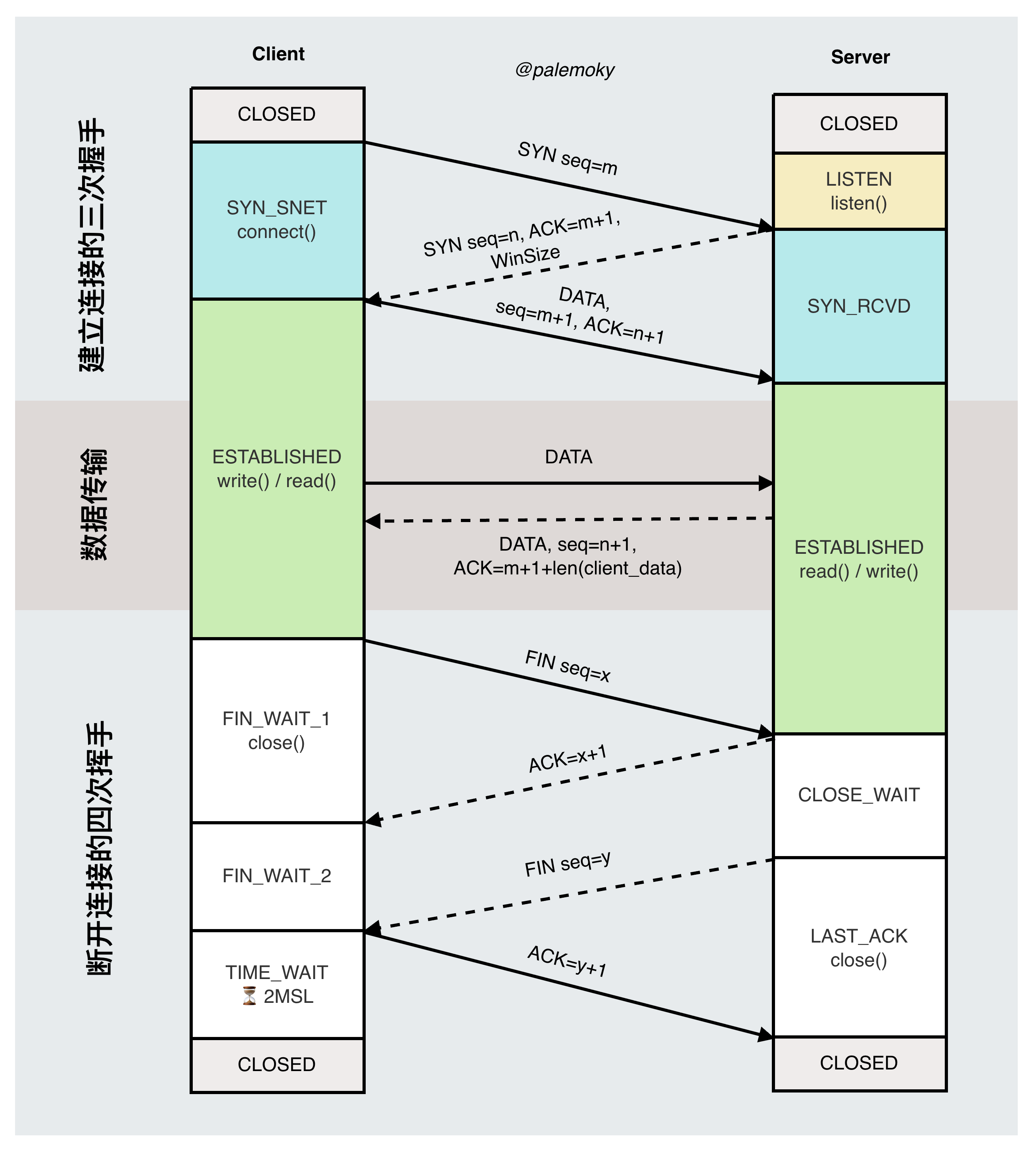
从图中可以看出,建立和断开连接都需要 4 次(客户端与服务端都需要向对方发送自己的状态并确认对方收到,因此两个客户端的状态往返总共需要 4 次)(在客户端与服务端同时打开连接时可以很清晰看到需要 4 次),只是在建立时服务端不需要传输数据,而将 SYN 和 ACK 合并为一次交换状态。但在断开时则因为服务端还有善后工作处理,因此必须分两次发送,所以需要 4 次。
注意:TCP 连接可以由请求方发起请求,由请求方或被请求方关闭请求(如服务端超时关闭客户端连接)。
TIME_WAIT 与 CLOSE_WAIT
| 状态 | 发生端 | 产生的原因 | 解决方法 |
|---|---|---|---|
TIME_WAIT |
主动关闭方 (通常是客户端) | 配置或架构问题。连接数过多、端口耗尽。比如客户端没有 keep-alive 建立大量连接,并使这些连接几乎在同一时间关闭。 |
使用长连接 (Keep-Alive);调整系统参数 (如允许重用端口 tcp_tw_reuse)。 |
CLOSE_WAIT |
被动关闭方 (通常是服务端) | 纯代码 Bug / 业务阻塞问题,收到对方关闭请求后,自己的代码没有调用 close()。 |
排查服务器代码,确保无论发生什么异常,最终都执行 socket 层的 close()。 |
这个 线上大量 CLOSE_WAIT 分析 的案例中,故障流程是:Server 向 MySQL 发起操作请求 -> Server 代码缺少 commit/rollback 导致 MySQL 超时发起关闭请求 -> Server 处于 CLOSE_WAIT 状态。在这个故障中,Server 是请求发起方,但最后却有大量 CLOSE_WAIT 状态,就需要使用 ss(netstat) 先查看 TCP 连接状态,再用 tcpdump 抓包分析,最后用 perf 快速定位到代码。
对于爬虫新手,如果没有复用连接,本地短时间内会产生大量的 TIME_WAIT 状态;如果没有连接关闭操作,则由于服务器连接超时,本地产生大量的 CLOSE_WAIT 状态。
服务器会为每个客户端连接创建新的进程或线程,从而达到并发处理的效果。
在 Linux 中,net.ipv4.tcp_fin_timeout和net.ipv6.tcp_fin_timeout记录了 2MSL 状态需要等待的超时时间,该值的取值范围在 30~300s。
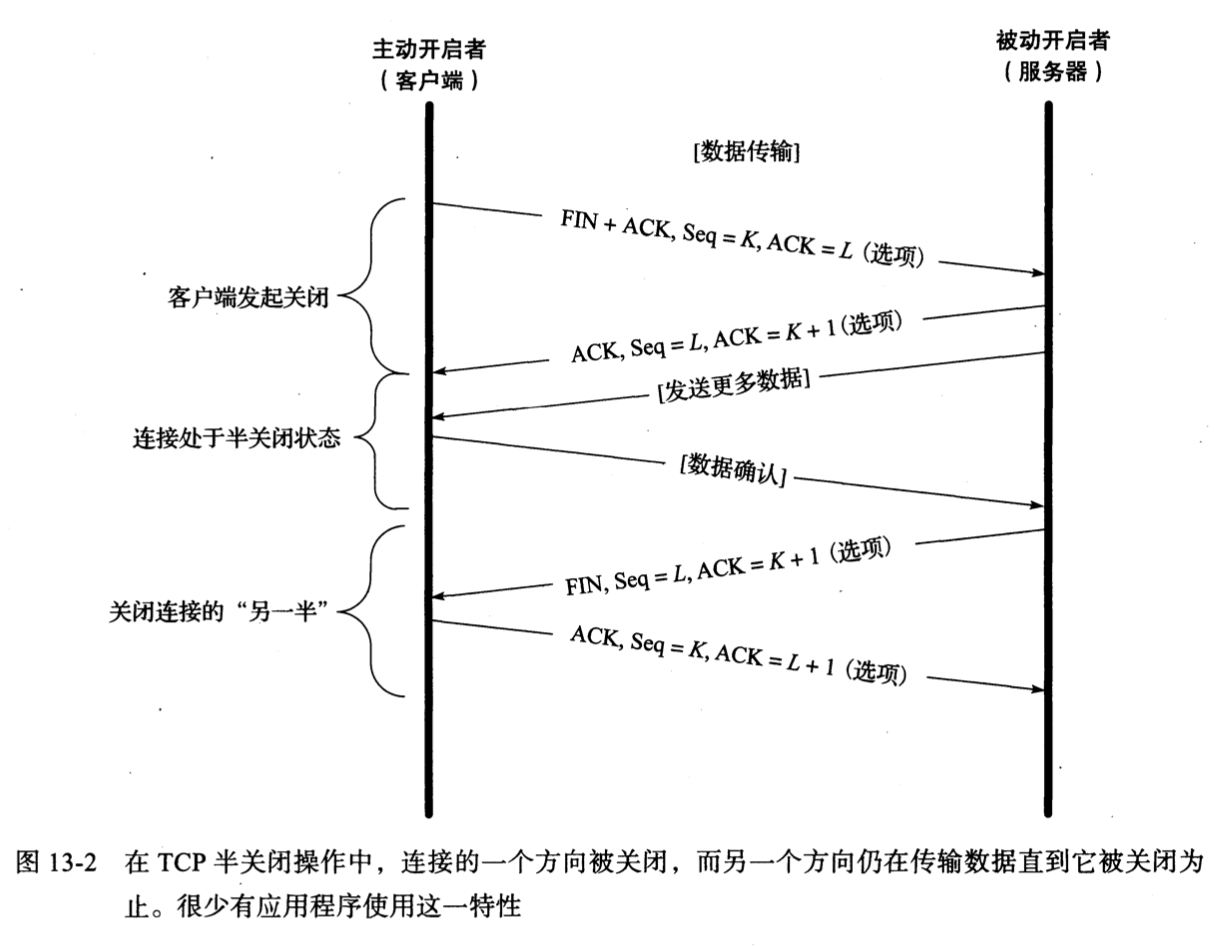
TCP 半关闭(少见) 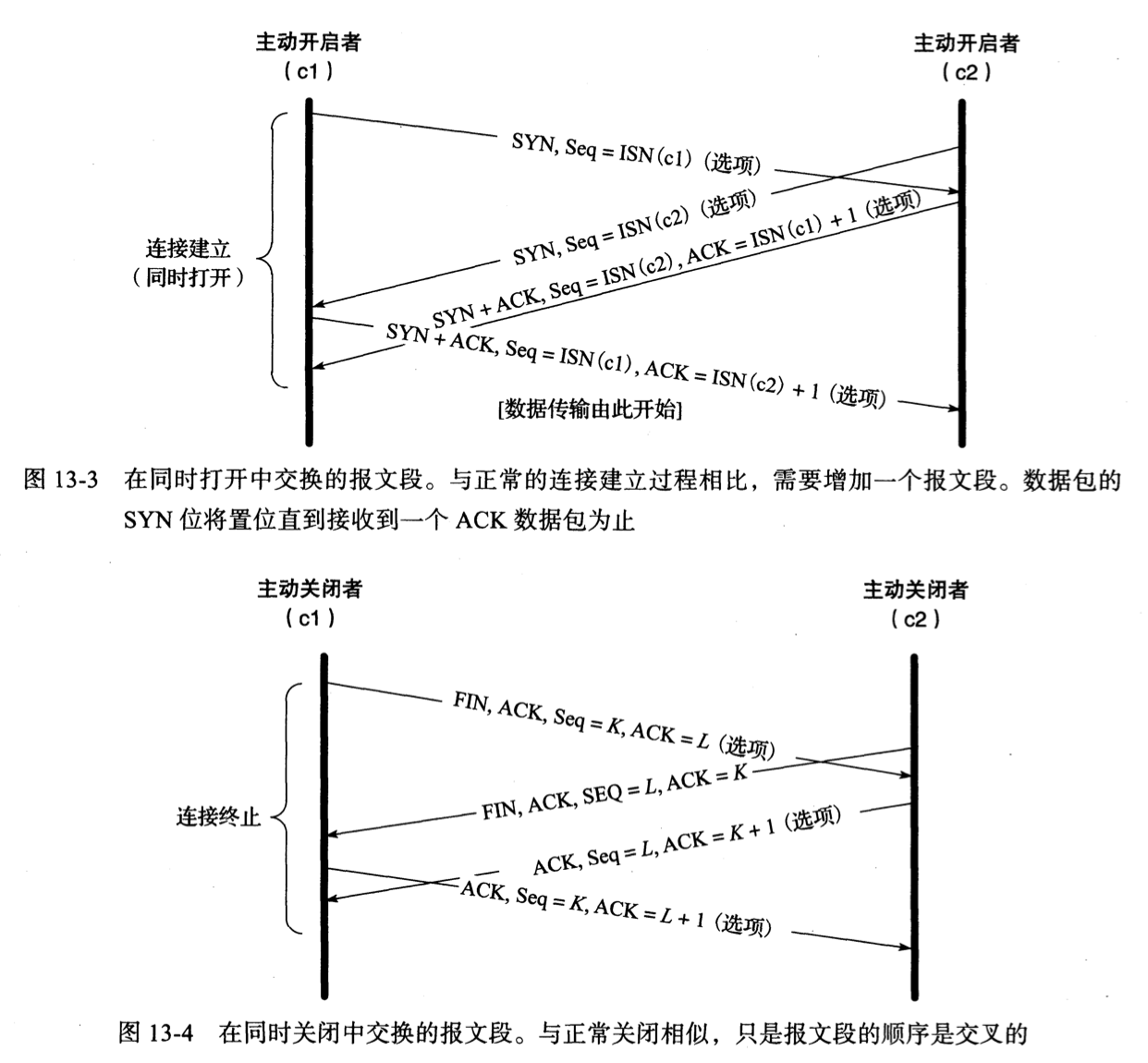
TCP 同时连接与关闭(少见) 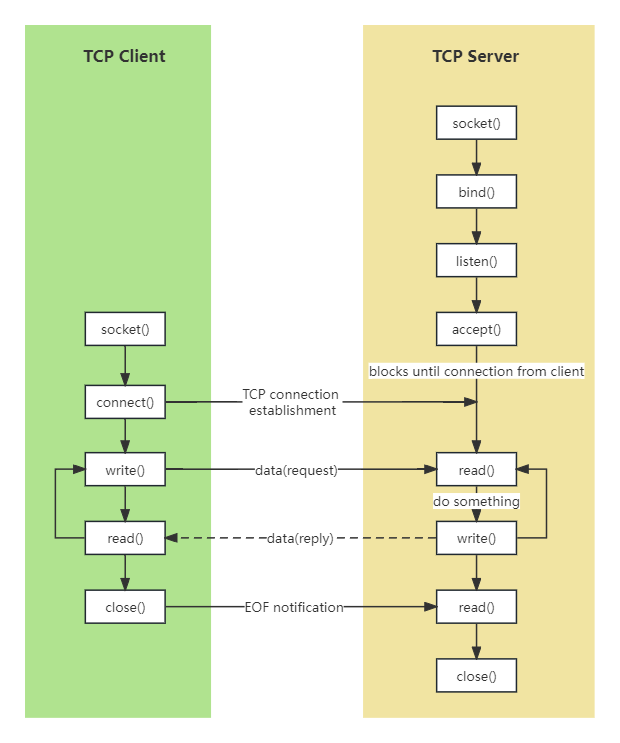
TCP 客户端与服务端通信交互过程 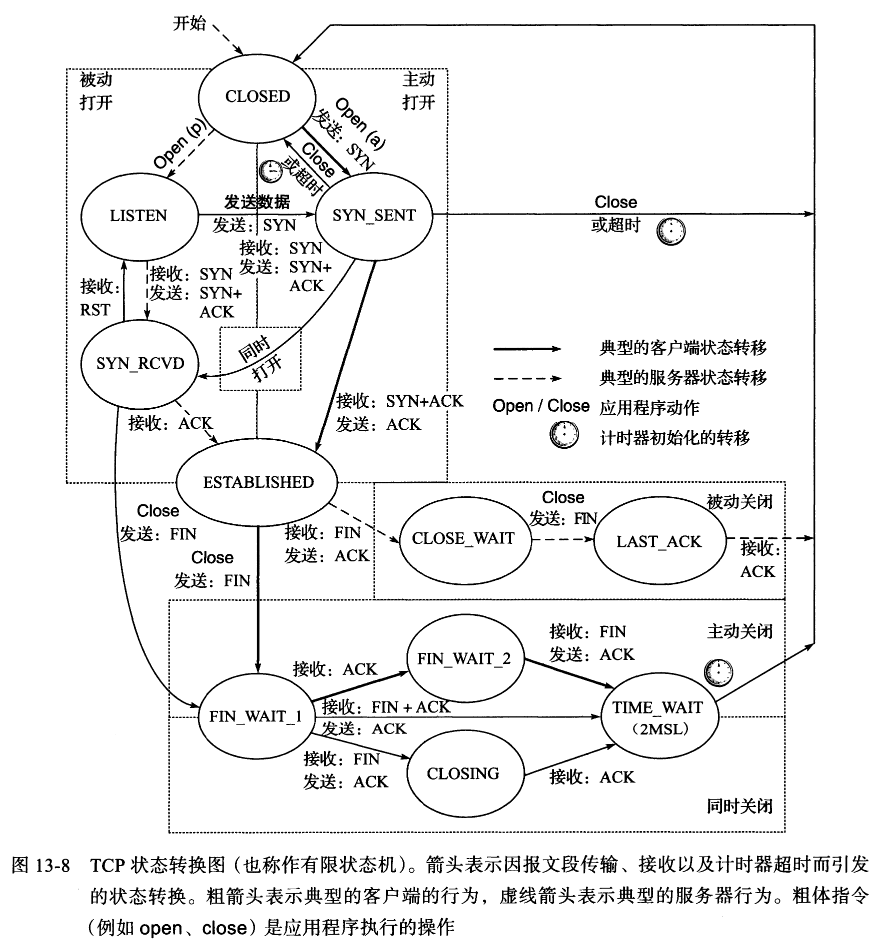
TCP 状态转换图
Linux 系统采用基于时钟的方案,并且针对每个连接为时钟设置随机的偏移量。随机偏移量是在连接标识的基础上利用加密散列函数得到的。散列函数的输入每隔 5 分钟就会改变一次。在 32 位的初始序列号中,最高的 8 位是一个保密的序列号,而剩余的各位则由散列函数生成。该方法所生成的序列号很难被猜出,但依然会随着时间而逐步增加。
滑动窗口¶
因为 TCP 是全双工协议,因此在建立连接时需要互相交换各自的 seq 和 winsize 等信息。每个 TCP 活动连接的两端都维护一个发送窗口结构和接收窗口结构。
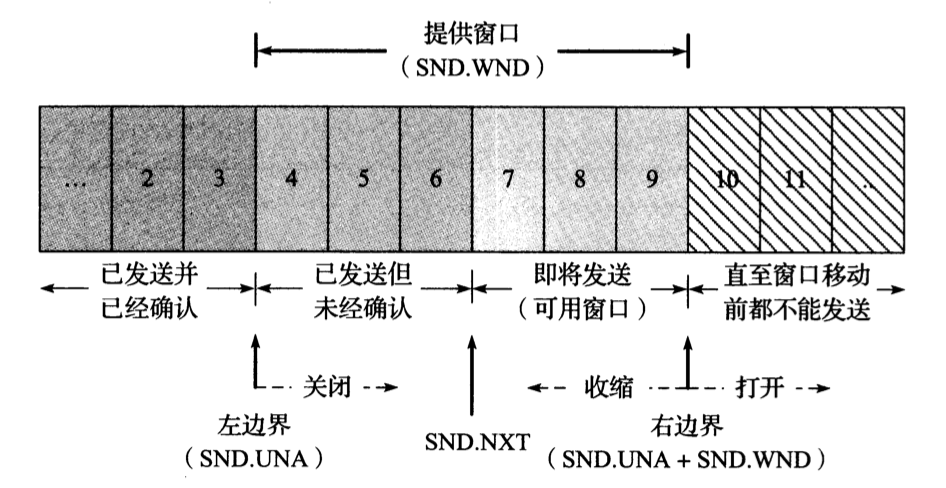
发送端窗口 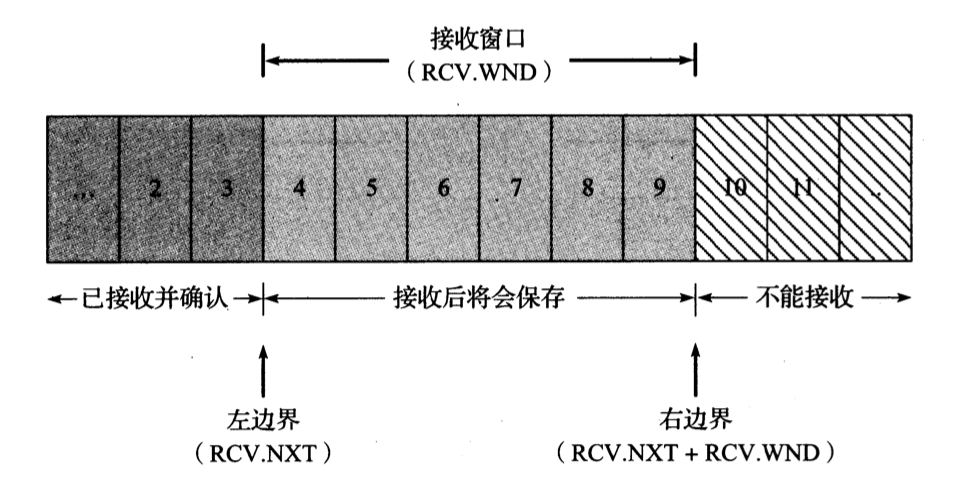
接收端窗口
TCP 通过接收端窗口来实现流量控制。当窗口值为 0 时,可以有效阻止发送端继续发送,直到窗口大小恢复为非零值。
为了防止接收端窗口更新的 ACK 丢失,发送端会采用一个持续计时器间歇性地查询接收端,看其窗口是否已增长。持续计时器会触发窗口探测的传输,强制要求接收端返回 ACK (其中包含了窗口大小字段)。
使用相对较大的接收缓存,即使在接收端应用处理数据前也能传输大量的数据。因此 Linux 在 2.6.7 之后的版本,支持发送方与接收方的缓存大小自动调整。
发送端与接收端窗口:
- 发送端不必传输整个窗口大小的数据
- 接收到返回的 ACK 的同时可将窗口右移
- 窗口大小可能减小,但窗口右边界不会左移
- 接收端不必等到窗口满才发送 ACK
接收窗口,rwnd,Receiver Window
拥塞窗口,cwnd,Congestion Window
发送窗口 = min(接收窗口,拥塞窗口)
拥塞控制¶
TCP 拥塞控制的难点在于怎样准确地判断何时需要减缓且如何减缓 TCP 传输,以及何时恢复其原有的速度。
TCP 通信的每一方都需要实行拥塞控制。
在 TCP 头部的 Options 中,会携带 TSval(Timestamp Value)和 TSecr(Timestamp Echo Reply),其作用如下
- 拥塞控制:时间戳选项可以帮助发送方和接收方计算往返时间(RTT,Round-Trip Time),以便更精确地进行拥塞控制。
- 序列号回环检测:时间戳也可以用于检测序列号的回环,即确保序列号在回绕时不会被错误地认为是旧的序列号。
需要注意的是,TSval 和 TSecr 的时间戳并不是真实的绝对时间戳,而是在建立连接时各自初始一个随机时间戳,然后开始计时,以避免主机时间设置错误和绝对时间戳时区导致的混乱。
发生拥塞时,通常难以检测,因此一般通过丢包率来判断是否发生拥塞。
虽然我们在建立连接时可以得知发送方与接收方的承载能力,但数据包传输过程中的路由器、交换机等设备的承载能力我们无法得知。因此,获得网络传输能力(拥塞窗口)的唯一方法是通过不断提升发送速率来探测,直至丢包(发生拥塞)为止。
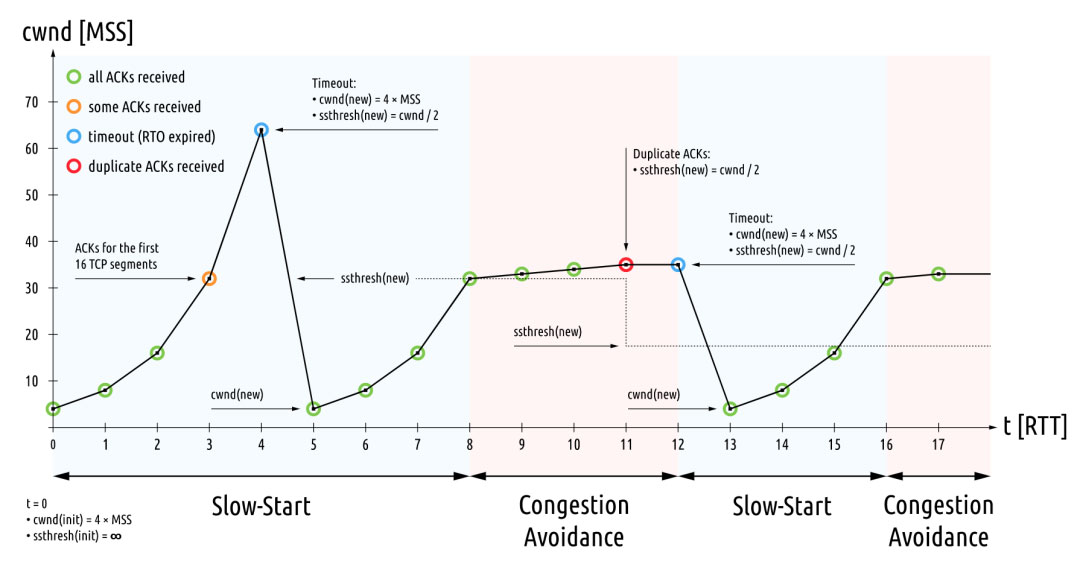
Reno 与 New Reno¶
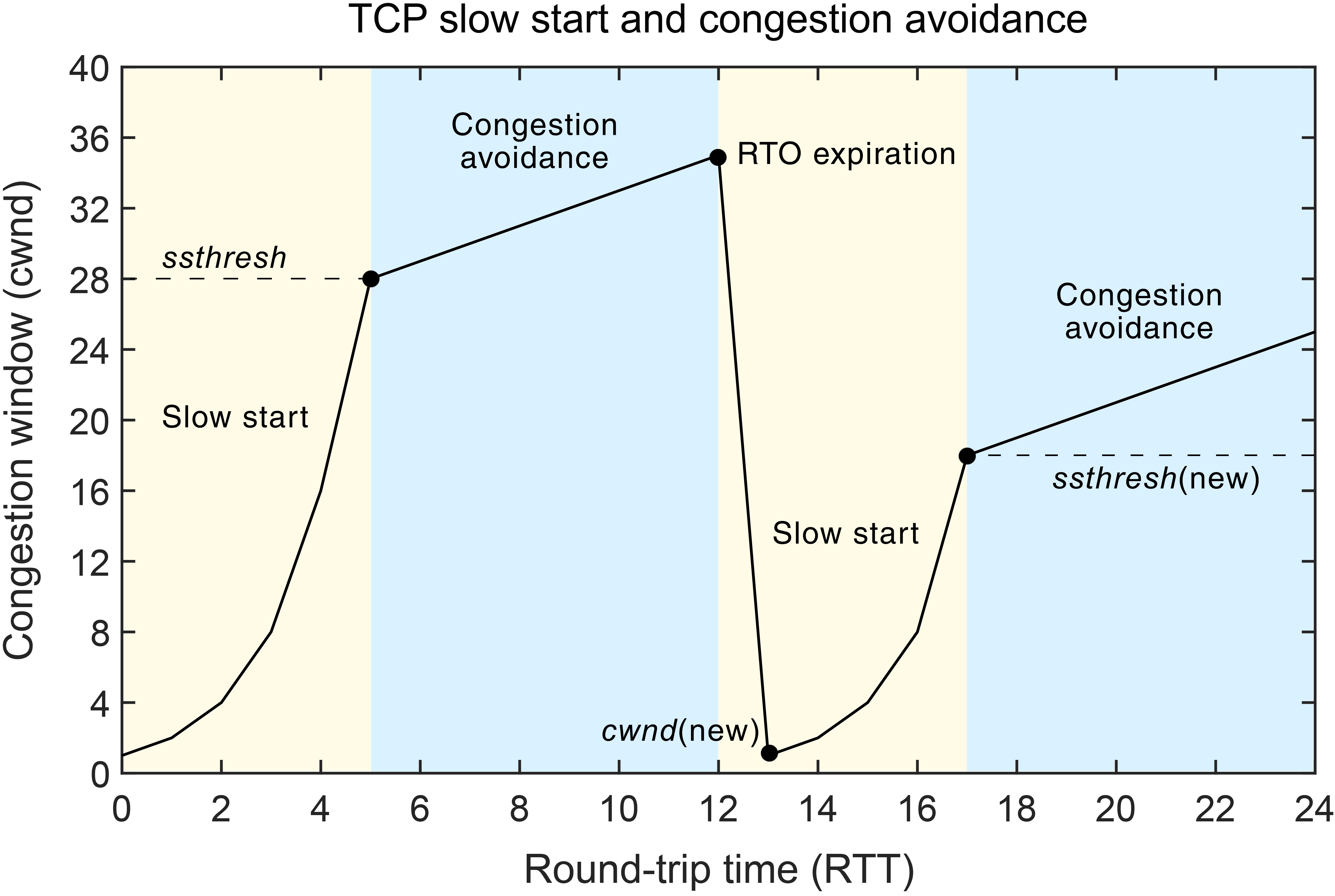
慢启动和拥塞避免(Reno) 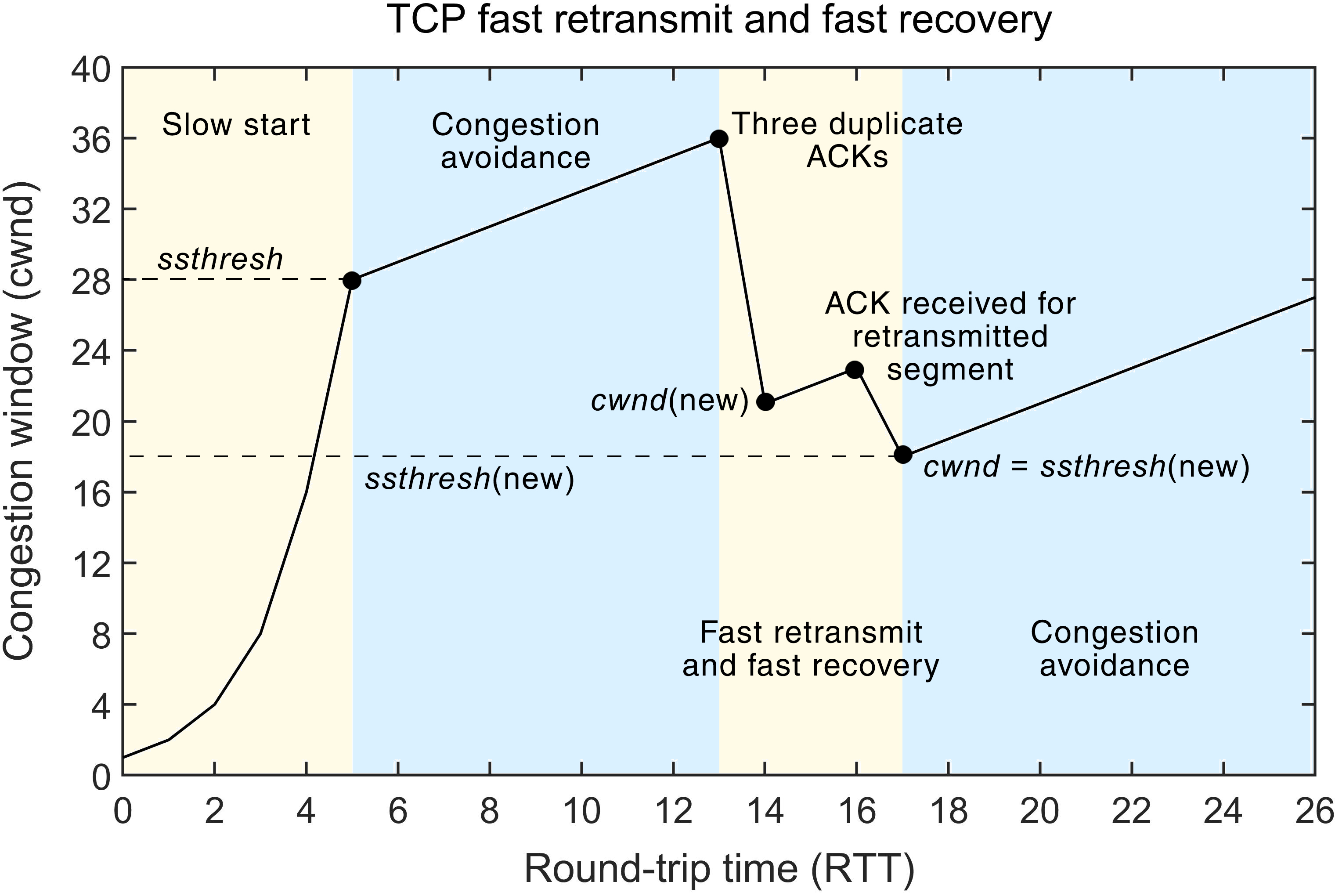
快重传与快恢复(New Reno)
- 慢启动和拥塞避免:在慢启动阶段,拥塞窗口呈指数增长(cwnd 在每收到一个 ACK 就会按 MSS 大小的倍数增加),进入拥塞避免阶段则是线性增长。
- 快重传与快恢复:发生拥塞时,拥塞窗口减半,而不是归零(主要解决发送拥塞发送速度掉底的问题)。
Linux 中在路径 /proc/sys/net/ipv4/ 下 tcp_congestion_control 和 tcp_available_congestion_control 查看默认和支持的拥塞控制算法。
CUBIC¶
Reno 算法(cwnd 表现为锯齿) 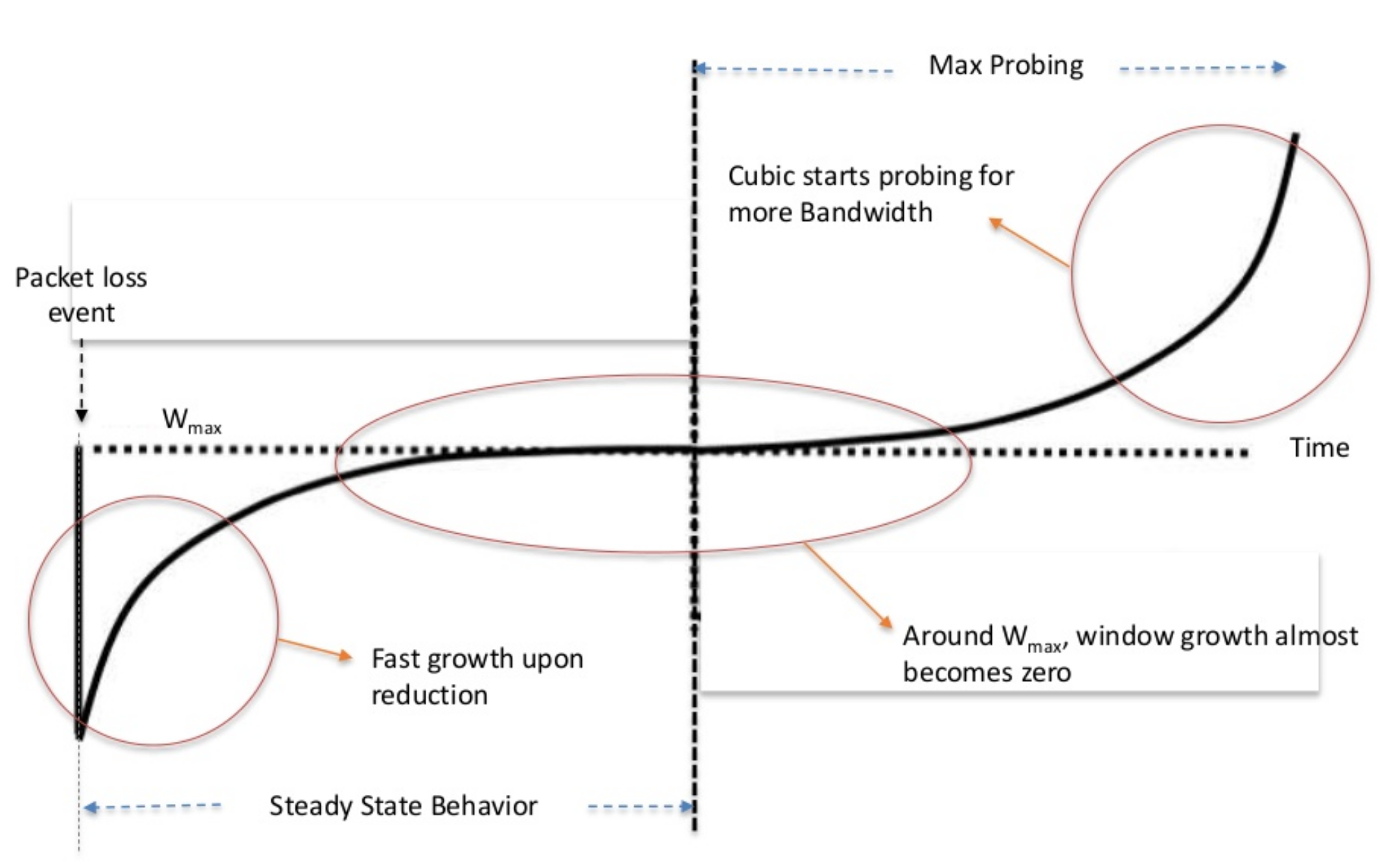
CUBIC 算法(https://www.slideshare.net/deawooKim/cubic-kdw)
CUBIC 优点:
- 能快速探测 cwnd,在高带宽、高延迟环境下表现更优
- 能维持在 cwnd 附近高速传输,而不会像 Reno 那样不断震荡
- 能探测并适应带宽更高的 cwnd,提升带宽利用率
CUBIC 缺点:
- 根据算法图可知,CUBIC 会长时间维持在 cwnd 附近,因此当带宽发生变化时,cwnd 跟随较慢
- 由于 cubic 的 cwnd 快速增长,导致低带宽网络迅速产生拥塞。网络设备的缓冲区被填满也导致了高延迟和抖动
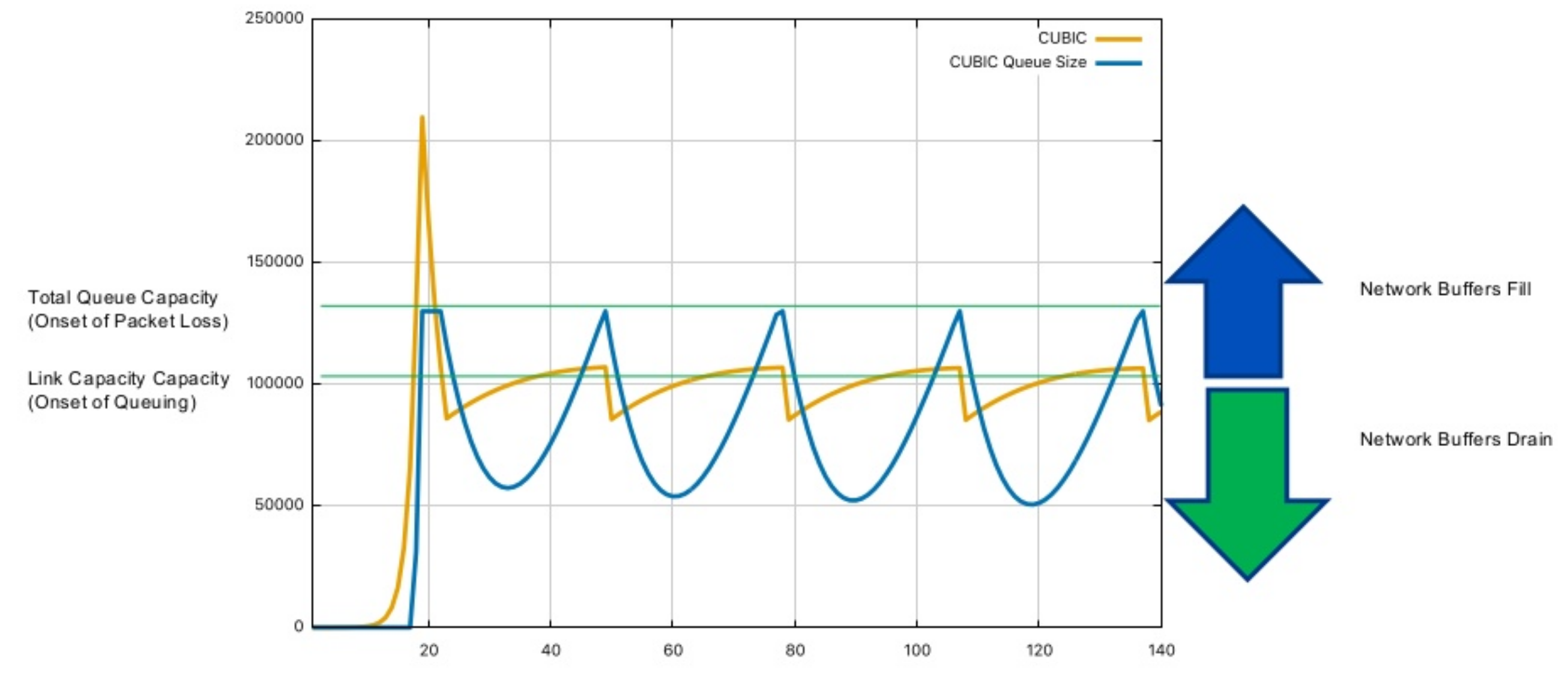 如图(来自 https://www.slideshare.net/slideshow/ausnog-2019-tcp-and-bbr/182584771),在横轴的 20 附近,CUBIC 快速发送超过 cwnd 和接收方 buffer 的数据包,随之出现丢包,CUBIC 的 cwnd 也降为一半,然后再逐步提升,并维持在带宽的最优 cwnd 附近,同时发送的数据包也在接收方 buffer 内高速传输。
如图(来自 https://www.slideshare.net/slideshow/ausnog-2019-tcp-and-bbr/182584771),在横轴的 20 附近,CUBIC 快速发送超过 cwnd 和接收方 buffer 的数据包,随之出现丢包,CUBIC 的 cwnd 也降为一半,然后再逐步提升,并维持在带宽的最优 cwnd 附近,同时发送的数据包也在接收方 buffer 内高速传输。
BBR¶
BBR(Bottleneck Bandwidth and Round-trip propagation time)是由 Google 在 2016 年提出的一种颠覆性的拥塞控制算法,现已集成在 Linux 4.9+ 内核及现代协议(如 HTTP/3 的 QUIC)中。
- 传统算法的痛点(基于丢包):如 Reno、CUBIC 等算法遵循“基于丢包(Loss-based)”的古典逻辑。它们会盲目且不断地提高发送速率,直到把中间路由器的缓冲区彻底撑爆导致“丢包”,才后知后觉地认为发生拥塞并紧急降速。在现代拥有超大缓冲区的网络设备中,这会引发极其恶劣的 Bufferbloat(缓冲区膨胀) 现象——数据包没丢,但像早晚高峰一样在极长的队列中干等,导致网络延迟剧烈飙升。
- BBR 的破局(基于模型):BBR 抛弃了丢包信号,改为主动交替探测网络的最大瓶颈带宽(BtlBw)和最小往返时间(RTprop)。它致力于将发送速率精准控制在“刚好填满物理管道,但绝对不让多余的数据包在路由器中排队”的完美数学临界点。
- 核心优势:
- 无视非拥塞丢包:在跨国网络、弱 WiFi 等由于物理抖动导致随机丢包的环境中,CUBIC 会误以为拥塞而把速度降至龟速,而 BBR 则由于模型测算的带宽不变,依然能无视丢包跑满全速。
- 超低延迟:彻底干掉了排队导致的 Bufferbloat 顽疾,使得网络在满载甚至超载吞吐下,依然保持着丝滑的低延迟。
超时与重传¶
一、基于计时器的超时重传
在大多数情况下,计时器超时并触发重传是不必要的(也不是期望的),因为 RTO 的设置通常大于 RTT(约 2 倍或更大),因此基于计时器的重传会导致网络利用率的下降。
二、快速重传
根据收到重复 ACK 来判断出现丢包并启动重传,而不等待计时器超时。
隐喻类比
TCP 中的数据传输就像现实生活中的物流,假设我们有一批货物(数据包)需要从 A 地(发送方)发到 B 地(接收方),B 地有一个仓库(接收方缓存)。我们第一次发货时需要知道 B 的地址以及仓库容量,以免发货过多导致 B 仓库无法容纳(数据包丢弃)。虽然我们可以预知 B 仓库的容量,但我们无法预知道路的运输能力(受拥堵和路线影响),因此我们通过不断提升发货量来探测道路的运输能力,以便快速运输完所有货物。
保活机制¶
当计时器被激发,连接一端将发送一个保活报文,另一端接收报文的同时会发送一个 ACK 作为响应。
Linux 中的保活参数设置:
| 参数 | 默认值 | |
|---|---|---|
| 保活时间 | net.ipv4.tcp_keepalive_time |
7200s (2h) |
| 保活时间间隔 | net.ipv4.tcp_keepalive_intvl |
75s |
| 保活探测数 | net.ipv4.tcp_keepalive_probes |
9 |
默认情况下 TCP 不会对保活报文加密,但应用层的保活机制(如 SSH)都会被加密,因此避免保活报文攻击。
UDP¶
由于 UDP 只是尽最大努力交付,不提供差错纠正、队列管理、重复消除、流量控制和拥塞控制,只提供差错检测,这些需要应用程序自行提供,因而它没有标识位,如用 SYN、FIN 和 RST 这些位来表示一个会话的创建或销毁。
UDP 与 IP 的攻击:
- 由于 UDP 没有流量控制,因此会被用于 DoS 攻击
- 重叠分片偏移
| DNS 类型 | 说明 |
|---|---|
| A | 将域名映射到 IPv4 地址 |
| AAAA | 将域名映射到 IPv6 地址 |
| CNAME | 将域名解析为另一个域名 |
| MX (Mail Exchange) | 指定邮件服务器 |
| TXT | 用于存储任意文本信息,如验证信息,SPF 记录等 |
| NS (Name Server) | 指定域名服务器 |
| PTR | 反向解析记录,即将 IP 解析为域名 |
QUIC & HTTP3¶
HTTP3 采用了基于 UDP 的 QUIC 协议,相比基于 TCP 的 HTTP1.1 和 HTTP2 的优势有:
- 快速建立连接:可在一个 RTT 内完成连接建立,显著减少延迟
- 连接迁移:当用户 IP 发生变化时(如 WiFi 到 5G),无需像 TCP 需要重新建立连接
- 多路复用:解决 HTTP2 中的队头阻塞问题
- 更好的拥塞控制:默认 BBR,但可以灵活调整
- 更高的安全性以及更低的开销:默认启用 TLS 1.3,相比建立在 TLS 上的 TCP,省去了握手的复杂性和延迟
- 开销低:QUIC 头部更简洁,减少了传输的开销
TCP vs UDP¶
TCP 的交付特点:
- 可靠性:TCP 提供可靠的数据传输,通过使用确认、序列号和重传等机制来确保数据的准确性和完整性。如果数据包丢失或损坏,TCP 会自动重传。
- 有序性:TCP 保证数据的有序交付,即接收方按照发送方的顺序重新组装数据。
- 流量控制:TCP 使用滑动窗口协议来控制发送方与接收方之间的数据传输速率,以防止过载或拥塞。
- 拥塞控制:TCP 通过监测网络拥塞情况和动态调整发送速率,以避免网络拥塞的发生。
UDP 的交付特点:
- 无连接性:UDP 是一种无连接的协议,意味着在通信之前没有建立连接的过程。每个 UDP 数据包都是独立的,相互之间没有关联。
- 不可靠性:UDP 不提供数据传输的可靠性保证,它不重传丢失的数据包,也不对数据包的顺序进行检查和修复。
- 较低的延迟:由于 UDP 的简单性,它具有较低的传输延迟。这使得 UDP 适用于实时应用程序,如音频和视频流媒体,其中时间敏感性较高,而可靠性相对较次要。
- 支持广播和多播:UDP 支持向多个接收方发送相同的数据包,这在某些场景(如实时通信、流媒体分发)中非常有用。

以太网数据结构 
TCP 可靠传输解决方案
应用层¶
DHCP¶
DHCP 的设计基于一种早期协议——BOOTP(Internet 引导程序协议),它目前已过时。
DHCP 常见的租期默认值为 12~24h。但在企业网络中,微软建议较小的网络采用 8 天(正好能覆盖 5 天工作日 + 2 天周末 + 1 天缓冲,避免了周一早上 DHCP 申请 IP 的“网络广播风暴”),较大的网络采用 16~24 天。客户机在租期过半时开始尝试续订租约。
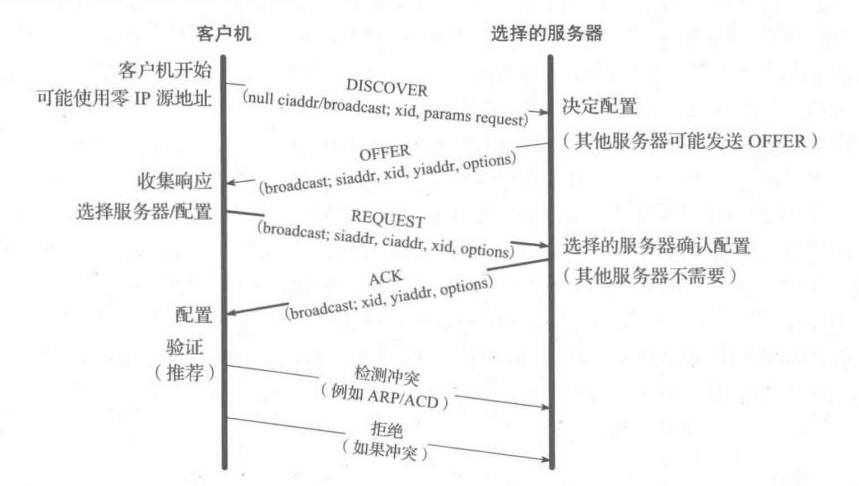
一次典型的 DHCP 交换。客户机通过广播消息发现一组服务器和可提供的地址,它请求自己想获得的地址,并接收到选定服务器的确认。事务 ID(xid) 用于将请求和响应匹配,服务器 ID 指出哪台服务器提供地址,并承诺将它与客户机绑定。如果客户机知道它想获得的地址,该协议可简化为仅使用 REQUEST 和 ACK 消息。
HTTP & WebSocket¶
WebSocket 是应用层协议,Socket 是传输层协议。
虽然 HTTP 和 WebSocket 都是基于 TCP,但 HTTP 的请求-响应模式通常被视为单工通信,而 WebSocket 则真正实现了全双工通信能力。
WebSocket 实现了在单个 TCP 连接上的全双工通信,适用于聊天、网络游戏等低延时场景。
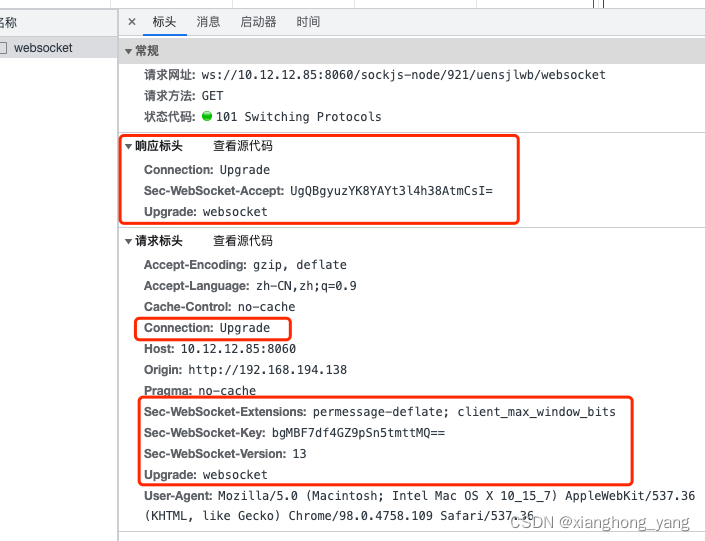
WebSocket 是与 HTTP 兼容的(与 HTTP 和 HTTPS 使用相同的 TCP 端口),这在防火墙阻止非 Web 网络连接的环境下是有益的。建立 WebSocket 连接时,首先建立一个 HTTP 连接,请求头部 Upgrade:websocket 升级为 WebSocket,这样做的原因是:
- 防火墙、代理、网关等中间件通常只支持 HTTP 协议,不支持 WebSocket
- 可以在握手阶段复用 HTTP 的能力,如身份验证、TLS 加密等
ws(WebSocket)和 wss(WebSocket Secure)类似于 http 和 https。
安全¶
该部分内容推荐查看 《图解密码技术》
加密算法¶
对称加密
- 3DES(利用两个或三个不同密钥对每个数据块进行三次 DES 加密)
- AES(通常在书写时也会加上长度,如 AES-128、AES-256)
非对称加密
- RSA(安全性基于大质数分解的困难性,不支持前向安全性)
- ECC(Elliptic Curve Cryptography,椭圆曲线加密系统):在相同安全程度前提下,ECC 使用的密钥长度小于 RSA 的密钥长度,同时支持前向安全性
- Diffie-Hellman-Merkle 密钥协商协议(在被监听的网络中协商出密钥)
前向安全性
- 定义:攻击者录制加密通信的内容,在某天攻击服务器获得其私钥,便可解密过去和未来与该服务器通信的加密内容
- 由于 RSA 的私钥固定,因此泄露 RSA 私钥就会导致前向安全问题,而基于 ECC 的 ECDHE 每次通信的私钥不同,则避免了此问题
由于计算机并不能做到本质上的随机,因此通常把用于模拟随机的数字称为伪随机数。
散列函数:MD5、SHA-1、SHA-2
消息认证码(HMAC):保证消息完整性的同时,防止消息被伪造
加密套件定义不仅仅是加密算法,还包括特殊的消息认证码算法、伪随机函数族、密钥协商算法、数字签名算法,以及相关的密钥长度和参数。
PKI、CA、X.509(格式有 DER、PEM(Base64 编码的 DER)、PKCS#7、PKCS#12)
安全协议¶
OSI 模型各层安全协议:
| 层数 | 名称 | 协议 |
|---|---|---|
| 7 | 应用层 | DNSSEC、DKIM、EAP、Diameter、RADIUS、SSH、Kerberos、IPSec(IKE) |
| 4 | 传输层 | TLS、DTLS、PANA |
| 3 | 网络层 | IPSec(ESP) |
| 2 | 链路层 | 802.1X、802.1AE、802.11i/WPA2 |
IPSec¶
L2TP 通常与网络层的 IPSec 结合使用:首先由 IPsec 建立一个加密的、认证的隧道(通常称为 IPsec 隧道)。然后,L2TP 在这个加密的隧道内建立自己的 L2TP 隧道。这种双层隧道结构确保了数据在传输过程中既被封装(L2TP)又被加密(IPsec),可以在公网上安全地传输私密数据,非常适合用于 VPN 服务,确保远程用户能够安全地访问内部网络资源。
目前主流的公司 VPN 解决方案都是通过 TLS 来实现安全访问内网资源的,如 Cisco AnyConnect 和 OpenVPN。TLS 基于以下原因取代了 L2TP/IPsec:
- 在移动设备上的广泛支持
- 由于 HTTPS 的广泛支持,TLS 的配置和部署更简单,尤其在存在 NAT 或防火墙的网络环境中
- 更好的性能和安全性
TLS¶
TLS 对数据加密发生在应用层和传输层之间。
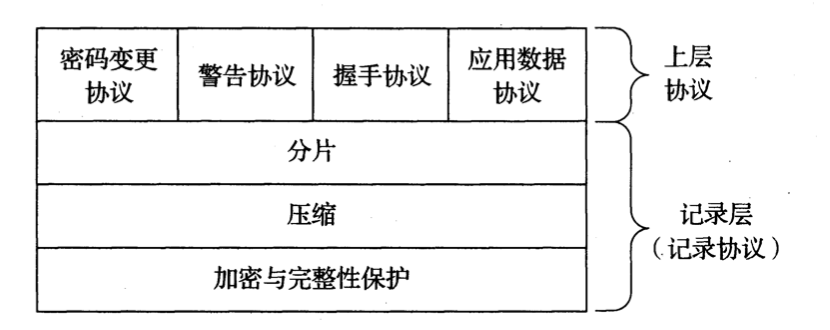
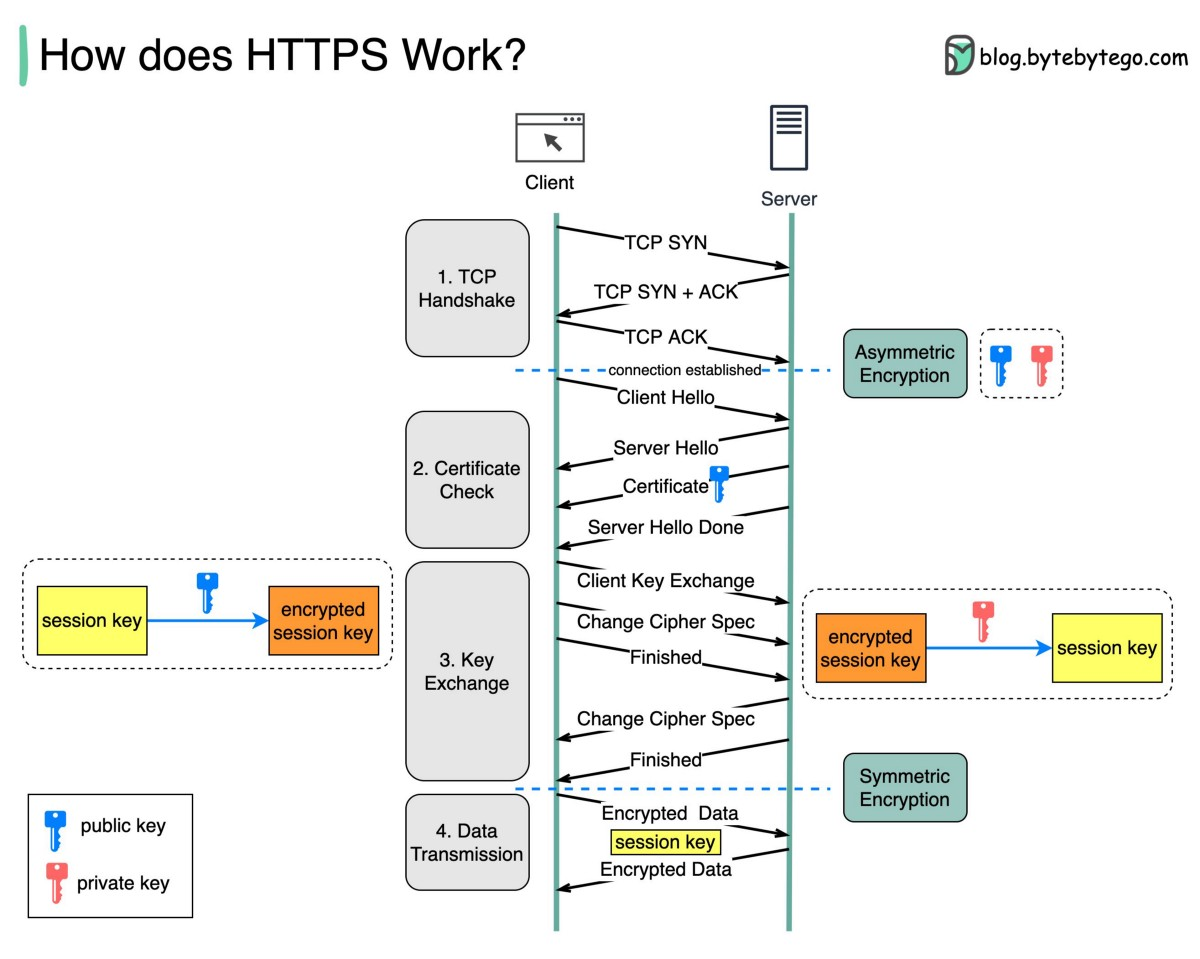
HTTPS 工作图解 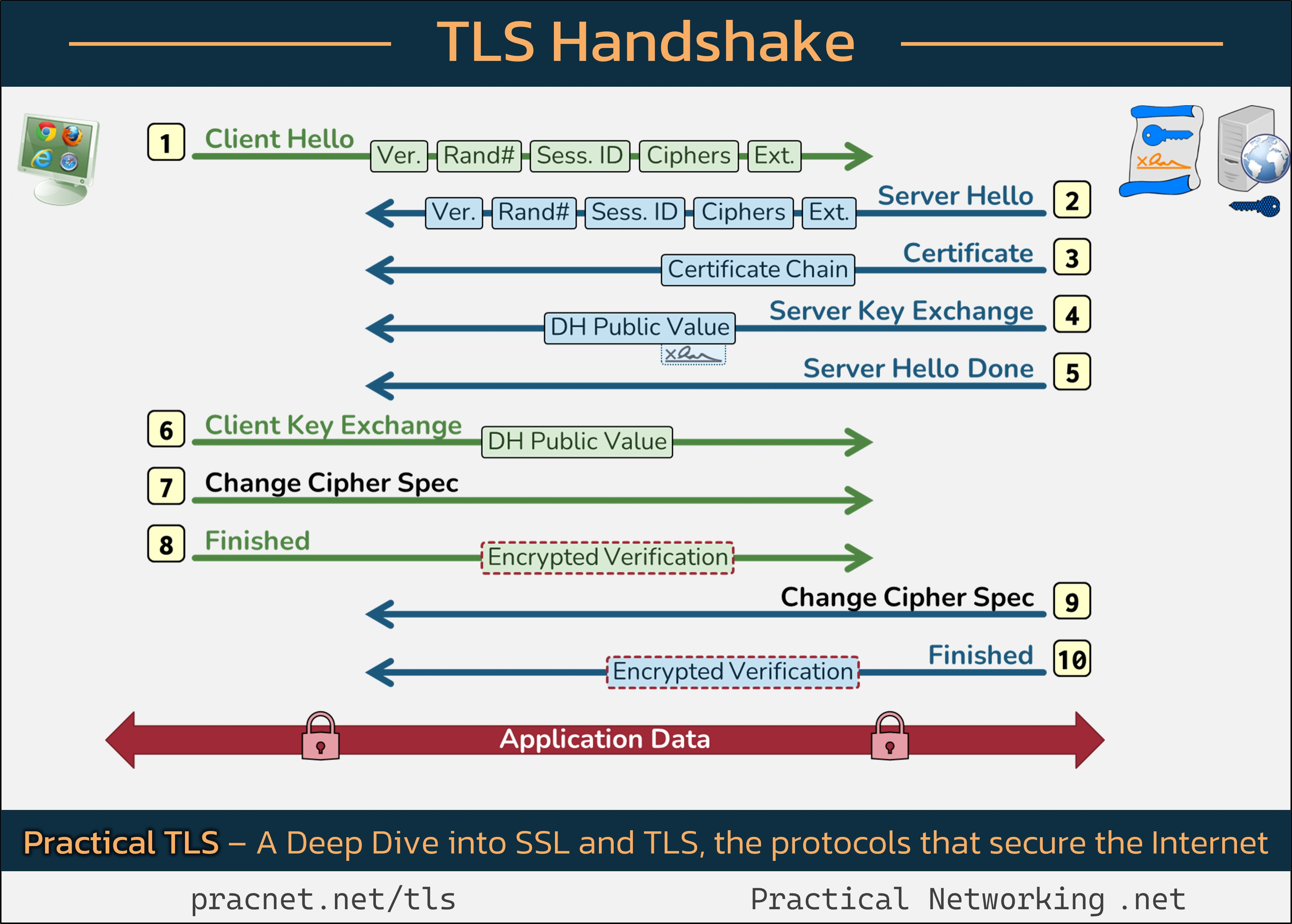
TLS 握手协议(Server 在初次握手后会生成一个 Session ID 给 Client,如果之后的 Client Hello 中携带的 Session ID 与 Server 缓存一致,则可用于会话复用,跳过完整握手的 Server Hello 之后的阶段,直接开始通信。)
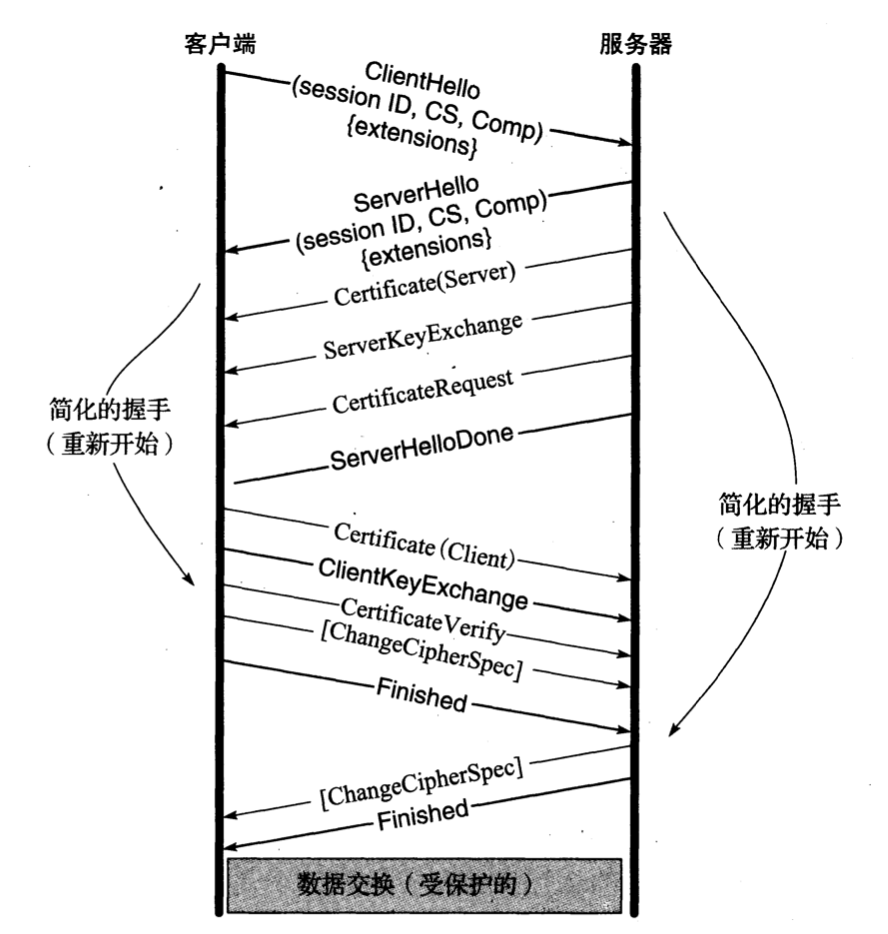
TLS 握手过程(不含 TCP 握手) 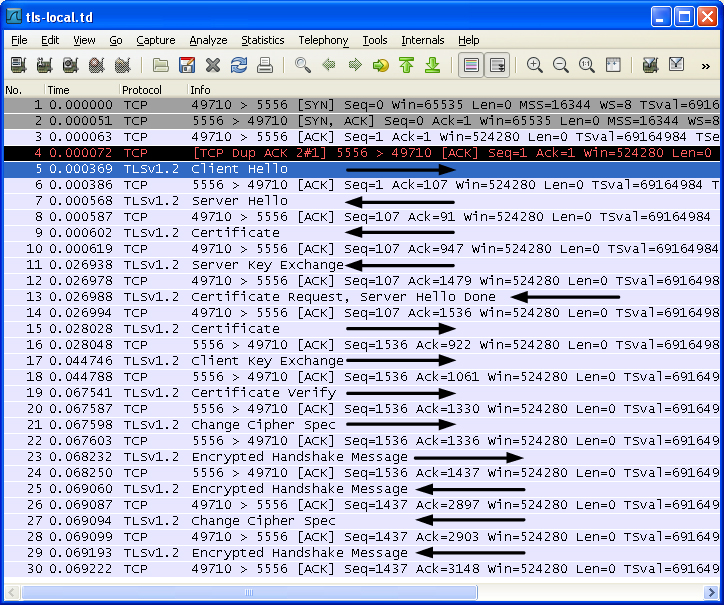
TLS 初次握手过程 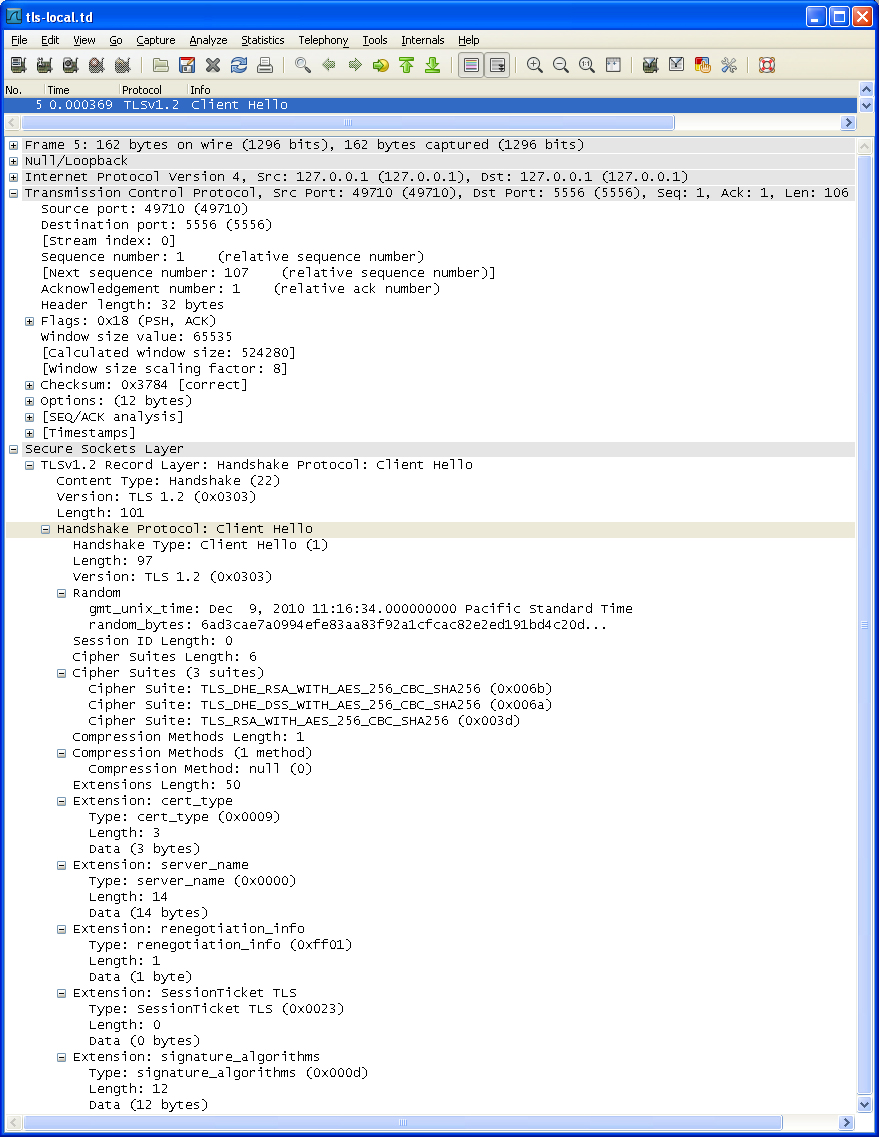
Random.random_bytes 用于产生密钥;由于是初次握手,Session ID Length 为 0;Cipher Suites 显示客户端支持的加密套件,并按推荐排序 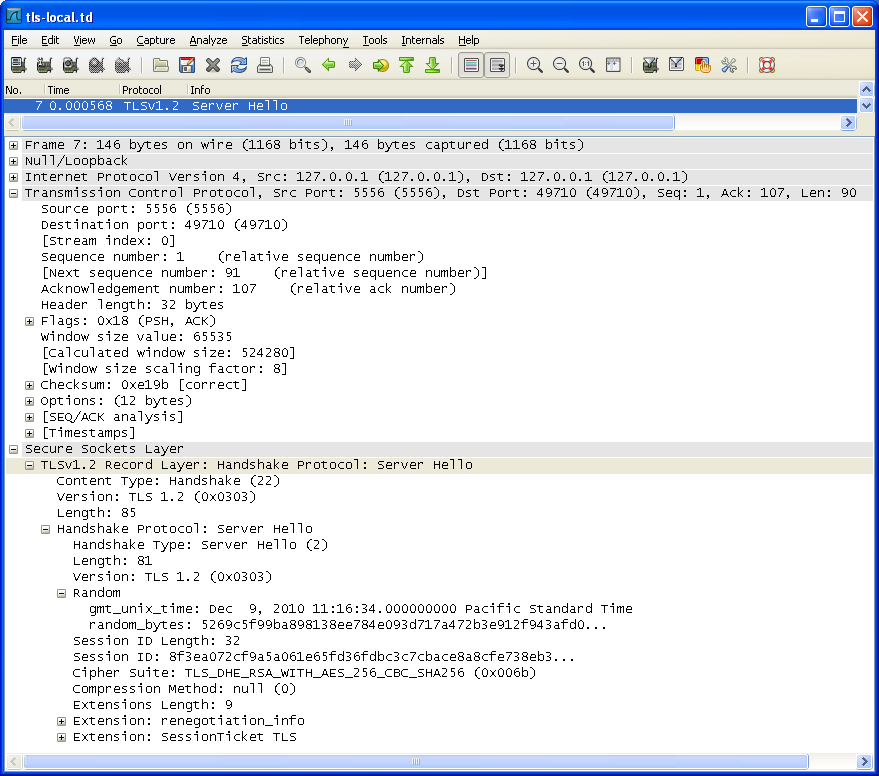
服务器中的 Random.random_bytes 同样用于产生密钥;返回的 Session ID 用于会话复用;Cipher Suite 中选定客户端提供的第一个加密套件(使用 RSA 证书的 DH 密钥协商,CBC 模式的 AES-256 算法用于加密,SHA-256 算法用于完整性) 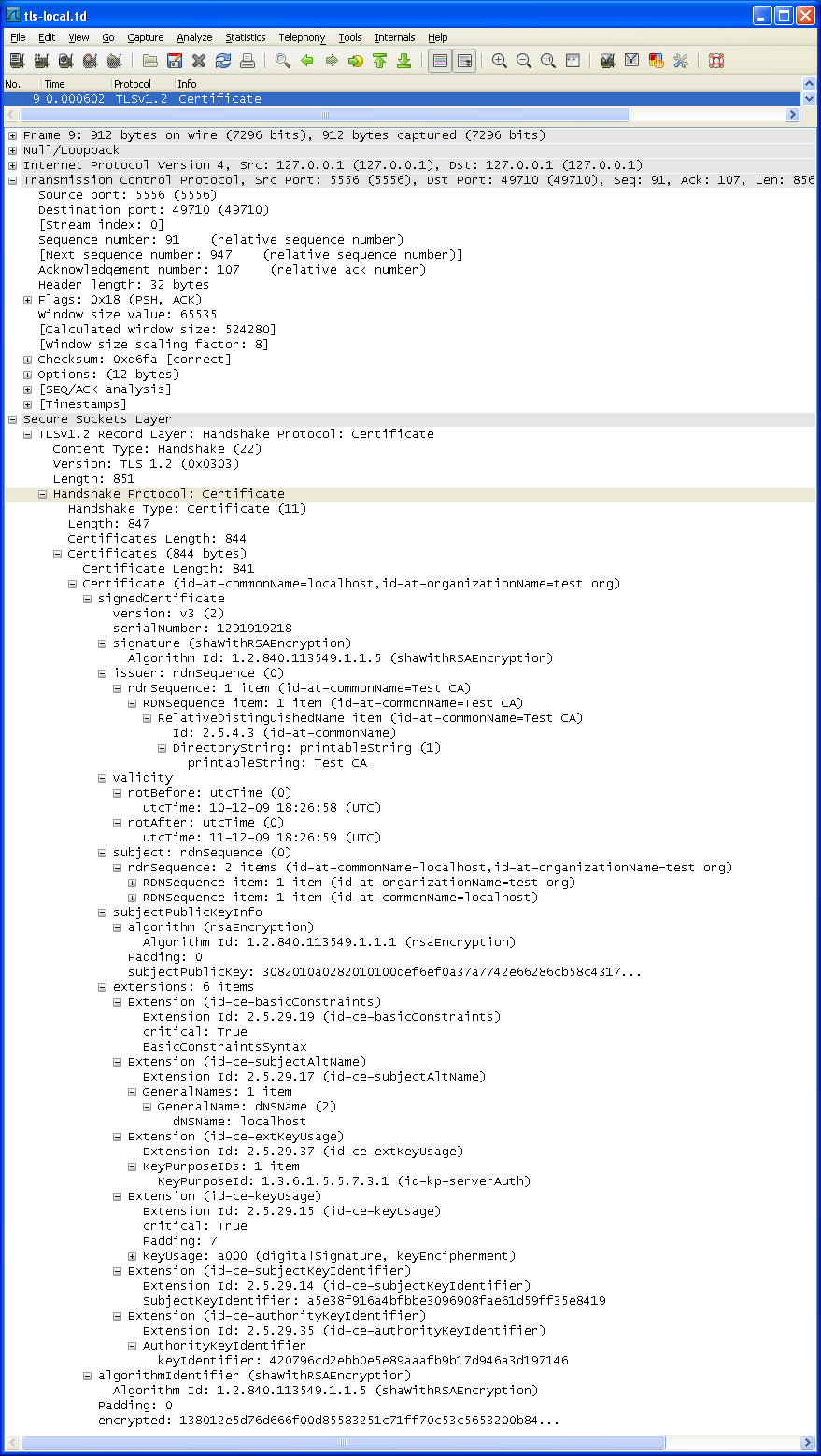
服务端返回经私钥签名的公钥,客户端验证证书链 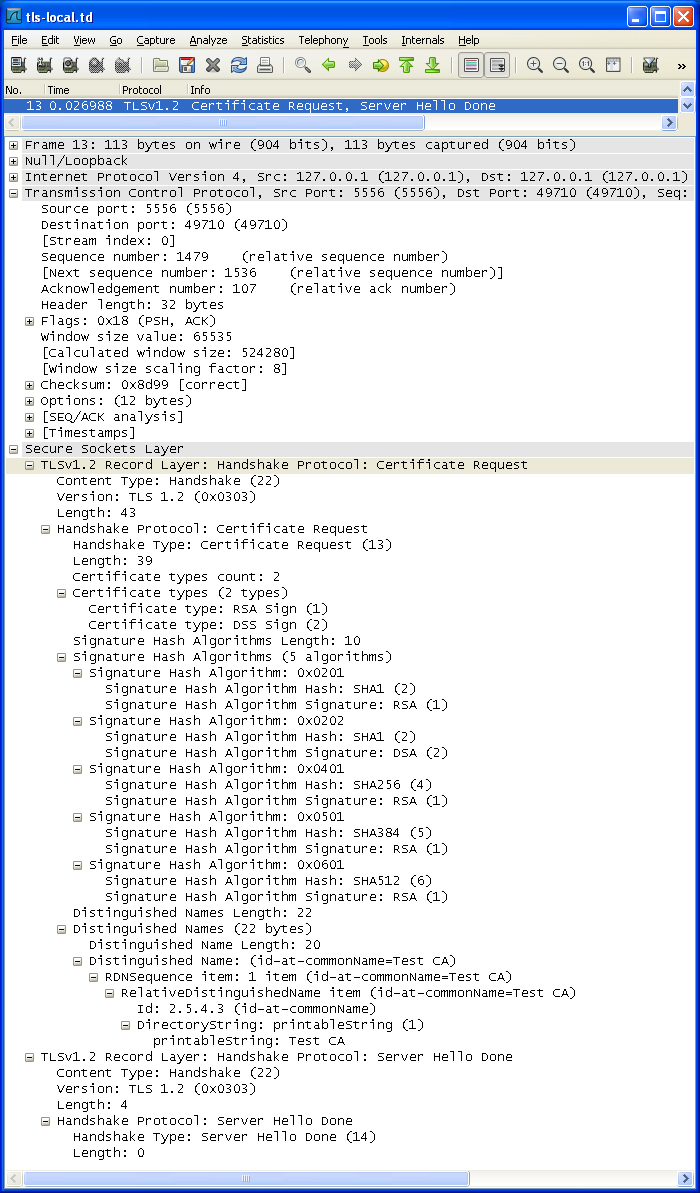
服务器验证客户端身份
DNSSEC¶
目前主流的 DNSSEC 有 DoH(DNS over HTTPS,443 端口) 和 DoT(DNS over TLS,853 端口)。DoH 相比 DoT 需要多一层的封装,因此性能较差,但其以广泛的支持和能通过大多数的防火墙与代理的优势,也非常常见。
经典协议层攻击与防范¶
TCP¶
- TCP RST 攻击:攻击者伪造源 IP(伪装成服务端或客户端),并通过网络嗅探获取当前 TCP 会话的正确序列号(Sequence Number),随后向任一方发送带有 RST 标志的数据包。接收方一旦校验序列号合法,便会认为对方发生严重异常,从而跳过四次挥手流程,瞬间强制关闭连接并销毁套接字。该攻击对 HTTP 和 HTTPS 均有效,因为 HTTPS 仅对应用层数据加密,而 TCP 头部为了中间设备(如路由器)的可靠传输必须保持明文。此类攻击曾常用于屏蔽未经审查的境外网站。根本解决方式之一是转向基于 UDP 的 QUIC 协议,通过在协议底层剥离 RST 控制权来抵御此类中断。
- SYN Flood(半连接泛洪攻击):在 TCP 三次握手阶段,攻击者发送大量 SYN 包却故意不回传 ACK 包,导致服务器的半连接队列耗尽,最终无法受理正常用户的新连接请求。传统的防御机制依赖于开启
SYN Cookies防御,而现代架构(如 Linux 6+ 内核)已支持依靠 eBPF 技术在网卡层面极速过滤并丢弃恶意包。 - 全连接攻击:攻击者按规矩完成完整的三次握手,与服务器建立合法的长连接。随后,攻击者刻意不发送业务数据,或者以极慢的速率发送请求(例如 Slowloris 滴水攻击),并持续保持连接活跃。这会导致服务器的全连接队列及线程资源被渐渐耗尽。通常需要借助代理层(如 Nginx)的请求超时限制、限制单 IP 并发连接数,或接入高防 WAF 等方式来防护。
- 零窗口攻击:攻击者建立连接后,在回复的 ACK 确认包中故意将自身的 TCP 窗口大小(Window Size)设为 0。服务器见状只得暂停发送数据,将积压的数据滞留在内核发送缓冲区中;同时为探知客户端何时恢复空间,服务器还会不断触发定时器发送“窗口探测包(Zero Window Probe)”。这不仅会导致服务端内存耗尽,更会无谓地空耗 CPU 资源。由于真实弱网环境下(如磁盘 I/O 满载)也会合法地出现短暂零窗口且能自行恢复,因此防御策略不应武断拒绝,而是配置“零窗口限时断连机制”,对持续恶意维持零窗口的连接强制切断。
DNS¶
- DNS 污染:当用户查询某个域名时,攻击者利用物理节点的距离优势,抢在真实 DNS 服务器之前将一个指向恶意 IP 的虚假响应返回给用户,导致用户被引导至错误站点。解决办法是使用 DoH 或 DoT,对 DNS 请求过程进行全程加密。
- DNS 劫持:部分网络运营商(ISP)在网关层面直接劫持拦截用户的明文 DNS 请求,将其强行重定向至导航页或植入广告的盈利网页。
TLS¶
- TLS 降级攻击:攻击者强行介入握手协商过程,通过篡改特定消息,诱导客户端和服务器端放弃原本安全的高级加密套件,退化为安全性较低的旧版算法(例如从 AES-256 降级到 AES-128,或从 SHA-256 降级到 SHA-1),以便后续更轻易地破解密文或伪造身份。
- SNI 劫持:在传统 HTTPS 建立加密通道前,首个握手包(Client Hello)的 SNI 字段必须以明文形式携带目标域名信息。攻击者借此可直接获知用户正在访问的站点并进行重置或阻断。目前的演进解法是推行基于 DoH/DoT 的 ECH(Encrypted Client Hello),在 TLS 握手初期便将 SNI 信息彻底加密。
- 重放攻击:攻击者即使无法解密 HTTPS 报文,也能截获其中一段合法的加密请求(如某笔转账操作),并向目标服务器原样重复提交成百上千次。若服务端应用层协议设计中缺乏“防重放机制”(如唯一的 Token/Nonce 随机数或严格的 Timestamp 时间戳校验),便会引发由于请求被重复执行而造成的安全事故。
HTTP¶
- 流量注入:部分运营商在介入网络响应时,通过恶意篡改明文传输的网页代码,强行插入
<script>或<iframe>标签以额外展示广告内容。可通过全站升级至 HTTPS 进行强制加密防范。